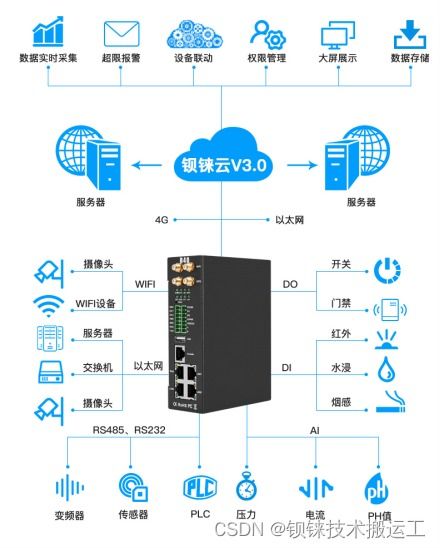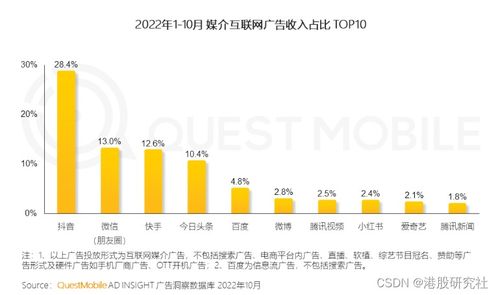
隨著大數據技術的快速發展,運維大數據處理及運維服務成為IT行業的熱門方向。對于初學者來說,系統性地學習這一領域至關重要。以下是一個循序漸進的學習路徑,幫助您從零開始掌握運維大數據處理及運維服務的核心技能。
一、打好基礎:掌握運維與大數據核心概念
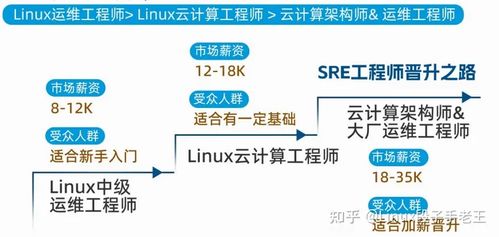
- 學習Linux操作系統基礎:作為運維的基石,熟悉Linux常用命令、文件系統、進程管理和Shell腳本編寫是必不可少的。建議從Ubuntu或CentOS入手,通過實踐加深理解。
- 了解網絡基礎:掌握TCP/IP協議、DNS、HTTP等網絡知識,理解網絡拓撲和故障排查方法。
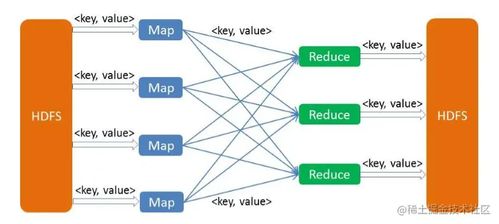
- 入門大數據概念:學習Hadoop、Spark等開源框架的基本原理,理解分布式存儲和計算的概念。了解數據采集、存儲、處理和分析的流程。
二、進階技能:掌握大數據處理工具與運維服務
- 學習大數據生態系統工具:
- 熟悉HDFS、YARN、Hive、HBase等Hadoop組件。
- 掌握Spark用于實時數據處理,學習Kafka用于數據流處理。
- 了解數據倉庫工具如ClickHouse或數據湖概念。
- 運維服務實踐:
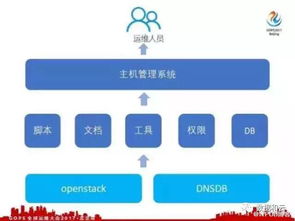
- 學習容器化技術,如Docker和Kubernetes,用于部署和管理大數據應用。
- 掌握監控工具(如Prometheus、Grafana)和日志分析工具(如ELK棧),確保系統高可用性。
- 了解自動化運維工具,如Ansible或Terraform,提升效率。
三、實戰與項目經驗
- 搭建實驗環境:在本地或云平臺(如AWS、阿里云)上部署小型Hadoop或Spark集群,模擬數據處理任務。
- 參與開源項目或實際案例:通過GitHub等平臺貢獻代碼,或嘗試處理公開數據集(如Kaggle數據),鍛煉問題解決能力。
- 關注運維服務場景:例如,設計一個數據 pipeline,從數據采集到可視化,并實施監控告警機制。
四、持續學習與社區參與
- 跟進技術動態:大數據和運維技術更新迅速,定期閱讀官方文檔、技術博客(如Apache官網、Medium)。
- 加入社區:參與論壇(如Stack Overflow)、技術群組或Meetup,與同行交流經驗。
- 考取認證:考慮獲取相關認證,如Cloudera的CCA或AWS大數據認證,以驗證技能。
五、常見挑戰與建議
- 挑戰:初學者可能面臨概念抽象、環境配置復雜等問題。建議從簡單項目開始,逐步增加復雜度。
- 學習方法:結合理論與實踐,多動手實驗;利用在線課程(如Coursera、極客時間)系統學習。
- 職業規劃:運維大數據處理涉及多個角色,如數據工程師、運維工程師,可根據興趣專注某一方向。
學習運維大數據處理及運維服務需要耐心和持續實踐。從基礎運維技能出發,逐步深入大數據工具鏈,并通過項目積累經驗,您將能夠在這一領域穩步成長。記住,實際操作和解決問題的能力是關鍵,祝您學習順利!