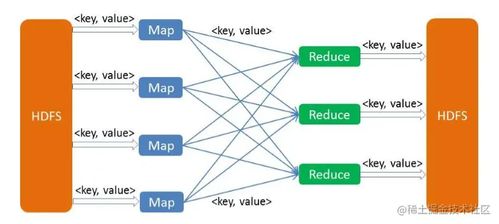
MapReduce是一種經(jīng)典的大數(shù)據(jù)處理編程模型和框架,最初由Google提出,后來在Hadoop生態(tài)系統(tǒng)中得到廣泛應(yīng)用。它通過將大規(guī)模數(shù)據(jù)處理任務(wù)分解為Map(映射)和Reduce(歸約)兩個階段,實現(xiàn)了分布式計算的并行處理。在本文中,我們將詳細(xì)解析MapReduce的核心原理、工作流程、優(yōu)勢與局限性,并結(jié)合實際應(yīng)用場景進(jìn)行探討。
一、MapReduce核心原理
MapReduce模型基于函數(shù)式編程思想,將數(shù)據(jù)處理任務(wù)分為兩個主要階段:
1. Map階段:輸入數(shù)據(jù)被分割成多個獨立塊,每個塊由一個Map任務(wù)處理,生成中間鍵值對(key-value pairs)。
2. Reduce階段:中間結(jié)果根據(jù)鍵進(jìn)行分組和聚合,由Reduce任務(wù)處理,最終輸出結(jié)果。
該框架自動處理數(shù)據(jù)分布、任務(wù)調(diào)度和容錯,開發(fā)者只需關(guān)注業(yè)務(wù)邏輯實現(xiàn)。
二、工作流程詳解
- 輸入分片:數(shù)據(jù)被分割成固定大小的分片,每個分片分配給一個Map任務(wù)。
- Map階段:每個Map任務(wù)處理一個分片,應(yīng)用用戶定義的Map函數(shù),生成中間鍵值對。
- Shuffle和排序:中間數(shù)據(jù)根據(jù)鍵排序并分發(fā)到相應(yīng)的Reduce節(jié)點。
- Reduce階段:每個Reduce任務(wù)處理一組鍵,應(yīng)用用戶定義的Reduce函數(shù),聚合結(jié)果。
- 輸出:最終結(jié)果寫入分布式文件系統(tǒng)(如HDFS)。
三、MapReduce的優(yōu)勢與局限性
優(yōu)勢:
- 高擴(kuò)展性:可輕松擴(kuò)展至數(shù)千節(jié)點處理PB級數(shù)據(jù)。
- 容錯性:自動處理節(jié)點故障,重新執(zhí)行失敗任務(wù)。
- 簡單編程模型:開發(fā)者無需關(guān)注底層分布式細(xì)節(jié)。
局限性:
- 不適合實時處理:批處理模式導(dǎo)致高延遲。
- 中間數(shù)據(jù)寫入磁盤:影響性能,尤其對于迭代計算。
- 復(fù)雜性較高任務(wù)需多次MapReduce作業(yè)。
四、實際應(yīng)用場景
- 日志分析:處理Web服務(wù)器日志,統(tǒng)計訪問頻率或錯誤率。
- 搜索引擎:構(gòu)建倒排索引,用于網(wǎng)頁排名。
- 數(shù)據(jù)挖掘:執(zhí)行聚類或關(guān)聯(lián)規(guī)則挖掘,如購物籃分析。
- 機(jī)器學(xué)習(xí):訓(xùn)練大規(guī)模模型,如協(xié)同過濾推薦系統(tǒng)。
五、與聯(lián)網(wǎng)信息服務(wù)的結(jié)合
在聯(lián)網(wǎng)信息服務(wù)中,MapReduce可用于:
- 用戶行為分析:處理用戶交互數(shù)據(jù),優(yōu)化服務(wù)推薦。
- 網(wǎng)絡(luò)監(jiān)控:分析流量日志,檢測異常模式。
- 內(nèi)容聚合:整合多源數(shù)據(jù),生成個性化摘要。
通過集成Hadoop生態(tài)系統(tǒng)工具(如Hive或Pig),可進(jìn)一步提升開發(fā)效率。
盡管新興框架(如Spark)在性能上有所超越,MapReduce作為大數(shù)據(jù)處理的基石,其思想和架構(gòu)仍深刻影響著分布式計算領(lǐng)域。對于歷史數(shù)據(jù)批處理和教學(xué)理解,它依然具有重要價值。在實際應(yīng)用中,結(jié)合具體需求選擇合適的框架是關(guān)鍵。